Bigger Data, Smarter Scaling
Parse.ly’s CTO, Andrew Montalenti was one of three presenters at the Times Open at the New York Times HQ on Wednesday, October 17. The theme of the event was “Bigger Data, Smarter Scaling” and who better to talk about scaling big data than the guys ingesting data from some of the web’s most highly-trafficked websites.
To give you a sense for what we’re dealing with at Parse.ly, just take a look at a couple of Andrew’s slides posted below.

What did our growth look like during our first year? Well we started with a handful of beta partners and then skyrocketed. Kudos to our engineers for keeping the infrastructure running better than ever during a time of crazy growth.
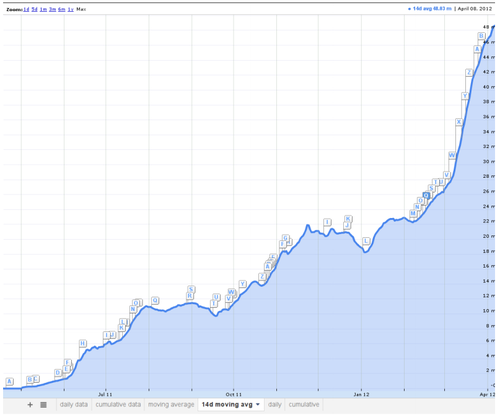
Scaling, and scaling quickly as we’ve had to do is not easy but luckily we’ve managed it quite well thanks to some smart decisions and technology choices. Big data is great and all, but without speed, you’re not really scaling effectively.
Our users of Dash and our API particularly value speed. Waiting minutes or even seconds for reports to load is unacceptable in fast paced newsrooms. Some of the best praise we’ve gotten is actually around the speed of Dash compared to the usual suspects (primarily Google Analytics and Omniture). Here’s some of the technologies that make it all possible.

Lastly, Andrew presented on some competing news standards including rNews, OpenGraph, and Schema.org. To enrich normal analytics data, Parse.ly scrapes publisher pages for additional metadata like author, section, publish date, thumbnail image, headline, etc.
When we first started, we had to write a custom crawler for every single publisher we brought on board. Our time got really, really good at writing these spiders quickly and effectively, but we knew it couldn’t scale for the long haul.
We therefore participated in the development of the rNews metadata standard, and through our work there, discovered that our product provides a great impetus for publishers to adopt open metadata standards.
On stage at the TimesOpen event, our awesome full-stack engineer Emmett Butler also released Mr. Schemato into the wild. Described as “a friendly semantic web validator and distiller that is making metadata cool again”, it eases the adoption and use of open standards. We are hosting an open Github project to collaborate on this effort across the industry.
Andrew was kind enough to post all of his slides online. You can find them here: https://speakerdeck.com/u/amontalenti/p/semantic-analytics-at-scale
Let us know if you’d like to talk more. You can find us on Twitter: @parsely
For info on future Times Open events, here’s the upcoming schedule: http://open.blogs.nytimes.com/timesopen-schedule/
– John Levitt, Director of Sales & Marketing