Loving a Log-Oriented Architecture
Jay Kreps created Apache Kafka to address his data integration needs at LinkedIn. He also wrote a widely-circulated essay about “The Log” that shows the motivation behind the system he created.
A few months later, he published a much more expanded version of that essay in the form of a short book for O’Reilly Media — pronounced “I Heart Logs”, but spelled, in Unicode as “I <3 Logs”.

I’ve read many materials about Kafka and Storm, including Nathan Marz’s
original book on Storm and distributed data processing, entitled “Big Data”, and Kafka’s documentation, which details its design. Each of these provided a helpful insight into each system’s architectural underpinnings, yet I really wish I had read Kreps’ “I <3 Logs” first.
(Unfortunately, it was only published recently, so this wasn’t even possible!)
That’s because in the distributed data processing ecosystem that has sprung up — Hadoop, Spark, Kafka, Cassandra, Storm, Elasticsearch, as examples — the log-oriented design principle seems to be among the most fundamental and widely useful, as it applies to nearly every distributed data system I’ve used in the last few years.
So, what is this log-oriented principle? I’d summarize it like this:
A software application’s database is better thought of as a series of time-ordered immutable facts collected since that system was born, instead of as a current snapshot of all data records as of right now.
Kreps summarizes this by analogy as follows: a bank account’s current balance can be built from a complete list of its debits and credits, but the inverse is not true. In this way, the log of transactions is the more “fundamental” data structure than the database records storing the results of those transactions.
The concept that Marz introduces in “Big Data” is “Lambda Architecture”. This is essentially the same thing. Marz frames the concept in more fanciful functional programming terms. He says, the current state of your software system can be calculated as a function over all of your past data. This is the “lambda” part — an uber function that can re-calculate the world. The data that serves as this function’s input: that’s the log. It’s the history of everything that has happened, in the rawest form possible.
But Marz also introduces an architecture to cope with the different technical demands put on a data system like this. He suggests that you may need to write that uber function twice — once for “batch” re-processing of all past data, and one for “real-time” processing of recent data. Kreps points out in his book, however, that this is more of a technical limitation of current data processing systems than a fundamental fact of life. Indeed, recent development work in the Spark community is demonstrating ways to unify batch and real-time processing using discretized streams (DStreams).
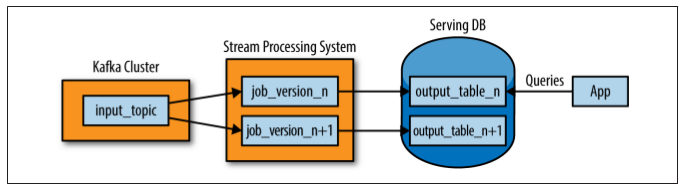
Kreps suggests he has achieved some success by running his log-backed stream processing systems in overdrive, re-configured to point at older logs. He says it may be easier to recalculate the world by making your stream processing temporarily over-provisioned, rather than rewrite your code atop a different batch-oriented computation framework that supports automatic scaling (like Hadoop + Elastic Map/Reduce).
Whether you call it log or lambda, these engineers make some strong points.
This way of thinking has been taking hold in the Clojure programming community, as well. Kreps recognizes this by calling out to Hickey (Clojure’s creator) and his company’s Datomic database, which is perhaps the first commercial database built atop a log-oriented architecture. As an example, Clojure’s persistent data structures — take a moment to look them up if you’re not aware of them now, because they’re cool — hold within them the full history of every change ever made to their state. This allows for idempotence and immutability of its functions, which simplifies reasoning about those functions.
The claim of both Marz and Kreps with Lambda and Log Architectures is that this same kind of idempotence/immutability simplification can be applied to distributed data systems. And, what’s more, if you start thinking this way, you better capitalize on the data you already have, while also solving integration, backup, and cross-region replication issues “for free”!
The unified log becomes an especially strong asset if you want to build multiple systems that are all producing indices, or materialized views, of your raw data, possibly even spread across different query layers backed by different database technologies.
To illustrate this, Kreps walks through many examples, and makes reference to many academic papers, open source systems, and the like. In this way, the short book serves as a strong introduction to the entire field of distributed computation and a new way of thinking centered around raw data. Unlike Marz’s “Big Data” which is dense and full of code examples covering Cascalog, Storm, and other specific systems, Kreps’ book is 100% discussion. There is little detail on the technologies behind that discussion, and no code snippets. The book is also programming language agnostic.
It’s a shorter, more fundamental book about a more fundamental architectural principle.
The Log is worth loving, and Kreps has written a book to make log lovers of us all. For context, I encountered log-oriented architecture myself as a Pythonista building production systems atop Apache Storm and Kafka, which was introduced to my team by our bright backend engineering lead who saw the folly in our brittle worker-and-queue systems. (We described our journey here, at PyData SV 2014.) Thus, for me, it was especially heartening to see a book espousing these ideas without a strong Java (or Scala, or Clojure) focus.
My team at Parse.ly now spends most of its open source energy on improving the experience for systems like Storm, Kafka, and Spark for Python programmers. We do this via open source projects like streamparse and PyKafka. Kreps’ book will now be required reading for new data engineers joining our team. If you care about large-scale distributed data processing in your own projects, I’d suggest you share this book widely with your colleagues.
Parse.ly is hiring! Interested in working on Storm, Kafka, Python, and web analytics data at scale? Send us a note at work@parsely.com with a link to your CV and/or Github.
Books referenced and reviewed: Big Data, Manning Press; I <3 Logs, O’Reilly. NOTE: The book links, when they linked to Amazon.com, included an affiliate tracking code.