Mage: The Magical Time Series Backend Behind Parse.ly Analytics
Building a time series engine is hard. Beyond the typical database management problems of data distribution, fault tolerance, and read/write scaling, you have the additional reporting challenge — how do you make it simple to query?
This article goes into depth on Mage, the backend that powers Parse.ly’s analytics dashboard.
Why did we need Mage?
In the case of Parse.ly, we had unique challenges that stemmed from the fact that we worked for the largest media companies on the web. So, when we rethought our backend architecture, we had some tough technical requirements for that new architecture.
For example, how do we…
- store behavior data on millions of URLs at minute-by-minute resolution, yet still allow roll-ups over time?
- support an almost limitless number of metrics, segments, and time dimensions per URL?
- deal with an ever-evolving set of crawled site metadata classifying those URLs?
- correct errors that might occur in our data collection in a matter of minutes?
- perform site-wide roll-ups, and even multi-site and network-wide rollups?
- do per-metric benchmarking, both to the site and to all data on record?
- group and filter URLs arbitrarily while performing calculations on their metrics?
And, how do we do this while maintaining sub-second query latencies? And without completely breaking the bank in our cloud hosting provider, Amazon Web Services?
The Challenge of Our Data
First, let me illustrate the scale of our data. We ingest about 50,000 data points per second from web browsers across the web. Our data collection infrastructure receives data from 475 million unique browsers monthly, and their browsing activity involves over 10 billion page views per month to sites, and many billions more events to measure things like time spent per page. This results in terabytes of raw data per month, and many terabytes of data in our archive.
(Update from the future: The above numbers were true as of 2016 or so, but are much larger today.)
We also continuously crawl sites for metadata, and we’ve built a web page metadata cache which is, itself, a few hundred gigabytes of ever-changing rich metadata, such as the full text of articles published, headlines, image thumbnail URLs, sections, authors, CMS tags, and more. We must continuously join this metadata to our analytics stream to produce the insights that we do.
As an illustration of the mere economic challenge of storing it all, I can observe that some of our largest customers (by traffic) add nearly $1,000/month to our Amazon CDN costs. This is the cost Amazon bills us merely to serve the tiny JavaScript tracker code to web browsers across the web. This commodified cost is just the starting point for us, as from that moment, packets of user activity start to stream to servers that we operate in Amazon EC2.
Now that you have a sense of the challenges of building an advanced time series store for web analytics, I will discuss how we attacked this problem.
A Lambda, or Log-Oriented, Architecture
I wrote a little bit about Lambda and Log-Oriented Architecture in my prior posts on this blog, “Apache Storm: The Big Reference” and “Loving a Log-Oriented Architecture”. This hinted at a foundational ideas for our data architecture here at Parse.ly: logs, streams, highly-parallel processing, and immutable data.
Highly parallel Python processes are used as the real-time stream processor for analytics data throughout; we wrote our own open source implementation of a Python protocol for doing this, called pystorm. We also wrote a project management and test framework, called streamparse, for making it all work smoothly with Python. The streamparse project is now a popular public Github project used by many companies and institutions for working with cluster-wide parallel processing easily from Python.

Pictured above: The first live demonstration of the streamparse open source library at PyData Silicon Valley.
Apache Kafka is used as the data backbone of our architecture. We have used Kafka for several years and even wrote our own full-featured and high-performance client library in Python, which is called pykafka. It is also a popular Github project.
As of recently, we also use Apache Spark for doing historical rebuilds and re-calculations of our data in batch mode. Kafka and real-time Python processing cores power our real-time pipeline; Spark, Amazon EMR, and S3 power our elastic historical rebuild layer. Combined, we get low latency, high throughput, and flexible elasticity for data processing.
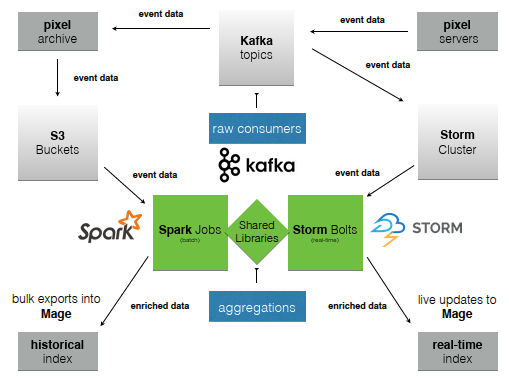
Diagram: Parse.ly high-level architecture, with batch analytics represented on the left and real-time analytics represented on the right, with shared Python code and Kafka topics acting as a data backbone throughout.
We discussed this architecture in more detail in a talk at PyData Silicon Valley, recorded in video form here on YouTube: Real-Time Logs and Streams. I also gave a follow-up talk on our use of streamparse in particular at PyCon. And most recently, I gave a talk covering Python’s multi-core (and multi-node) computing landscape at PyData NYC, entitled “Beating Python’s Global Interpreter Lock (GIL) to Max Out Your CPU’s”. It shows how Kafka and S3 data stores can fit into the broader Python landscape of tools for parallel computing, such as multiprocessing, joblib, and ipyparallel. The need for multi-node parallelism for the scale and resiliency of this problem domain drove our innovation here.
Once we could reliably process tens of thousands of events per second in a real-time data pipeline, our next job was to build a time series store to keep query the data effectively. Mage, then, is our home grown system that takes all of this live, streaming analytics data and makes it available for instantaneous time series analytics in our dashboards and APIs. Mage is not an open source component, but it is a system-level abstraction we’ve built internally atop powerful distributed databases and refined data models.
In particular, Mage lets us query across our CrawlDB (crawled document store) and our TrackDB (content-grouped time series analytics store) in a unified way, while supporting elastic scalability for real-time data and batch/historical data processing. It is also a unified query layer that powers both our Content Analytics dashboard product and our Content API product.
Immutable Events at the Core
In my post about log-oriented architecture, I wrote that the core principle that has taken hold about this design pattern is as follows:
A software application’s database is better thought of as a series of time-ordered immutable facts collected since that system was born, instead of as a current snapshot of all data records as of right now.
We made this principle core to our new system design.

Pictured above: Andrew (CTO) and Keith (Backend Lead) discuss Parse.ly’s log-oriented architecture.
Data enters our system as raw Kafka topics, which contain the “firehose” of user activity from all of our sites. This data does not follow a partitioning scheme and since data is collected from servers across multiple geographic regions, it is not even guaranteed to be in time order.
One of the first things that happens to this data is that it is backed up. A Python process automatically uploads all the raw logs to Amazon S3, where they are grouped by customer account and day, after applying rules related to our privacy policy, such as expunging IP addresses for certain sites.
The data flows into highly-parallel processing topologies via Python “spouts”. The core code runs in our “writer” topology. Its spouts spread the data throughout our data processing cluster, utilizing Kafka consumer groups.
The data is batched for performance reasons and writing them to a distributed data store that provides URL grouping and time ordering (Cassandra). This distributed data store is primarily a staging area. It contains trailing 7 days of raw event data storage. Its primary purpose is to group and order — and then provide a mechanism to easily and continuously index (and re-index) the data in our time series database.
After data is ack’ed and written to this staging area, a new Kafka topic receives a signal that indicates that a URL’s analytics data need to be refreshed. This signals another topology that it’s time to build up several time series materialized views of the data.
Building a Time Series Index
This other code runs in our “indexer” topology. It is this topology that looks for URLs that have changed, queries for the most recent time series data from the staging area, performs a streaming join from our cached web crawl metadata, and writes time series records to our time series database.
Records are written in several “time grains” or “time rollup windows” to allow for various degrees of query flexibility, and to gain compression benefits as data ages out of real-time views.
- Raw records are kept for 24 hours. This allows the best possible query flexibility, but since it’s several hundred gigabytes of data per day, it is not feasible to hold the data longer than this.
- “Minutely” records (5min rollups) are kept for 30 days. This allows us to spot fast-moving real-time trends in data and draw fine-resolution timelines for individual URLs and posts. The grouping of data into 5min rollups immediately reduces query flexibility, but it cuts down data storage considerably and lets us hold onto the data longer.
- “Daily” records (1day rollups) are kept for as long as the site has paid for retention. In time series data modeling, we determined that 1day rollups tend to be best when you are trading off cost of storage vs rollup capabilities. The 1day records still allow timezone adjustment, dramatically reduce the number of records to model site traffic in a single day, and grant us immense savings on repeated metadata attributes.
Data is also heavily sharded across a large cluster of machines to allow for both rapid query response times via in-memory caches and page caches spread across many solid-state disks. The sharding scheme involves month-grouping all the 1day samples, day-grouping the 5min samples, and hour-grouping all of the raw events.
Aggregating the Time Series Data
Aggregation is supported on all of our data through a number of neat tricks. For example, members of our team have done work with probabilistic data structures before, and we make use of HyperLogLog to do efficient cardinality counts on unique visitors. We use fast sum, count, average, and percentile aggregations via queries that resemble “real-time map/reduce jobs” across our cluster. We support arbitrary filtering via a boolean query language that can reduce the consideration set of URLs on which data is being aggregated.
Integer values and timestamp values are efficiently stored thanks to run-length encoding. The data storage of raw visitor IDs and repeated string metadata attributes are reduced in cost, by only storing their inverted index. For cluster scale-out here, we are leveraging the magic of Elasticsearch.
All Wired Together, It’s Magic
We are extremely pleased with the way Mage has turned out, and very excited to continue to hack on what must be one of the web’s largest and most useful time series databases. Understanding content performance across billions of page views and millions of unique visitors has been an eye-opening experience, and being able to deliver insights about this data to customers with sub-second latency has been a real “wow” factor for our product.
It has also allowed us to understand many more dimensions of our data than ever before. As my colleague, Toms, put it in a prior blog post about the thought that went into Parse.ly’s UX our challenge “now lies in finding how to tell the million stories each dimension is able to provide”.
As a summary of some of the new metrics that Mage now supports:
- page views second-by-second, minute-by-minute throughout
- de-duplicated visitors and segmented visitors available throughout
- engaged / reading time (aka “engaged time“) throughout
- social shares and interactions, and click-per-share rates
- sorting data by time, visitors, views, or average engagement
- contextual metrics, e.g. time per visitor and time per page, throughout
- breakouts by device
- breakouts by visitor loyalty
- breakouts for multi-page articles
- breakout of traffic recirculation between pages
- benchmarking on all metrics, e.g. above/below site average, percent of site/rollup total
- rollup reporting across multiple sites
And we will only continue to add to these over time as we learn even better ways to understand content and audience.
Summary
- We re-built Parse.ly’s backend atop a “lambda architecture”.
- A generic content and audience time series data store, called Mage, was born.
- Mage translates analytics requests into distributed queries that return time series aggregates.
- This new backend now powers a single-page application in JavaScript that is a thin client on a rich set of capabilities.
How Has Mage Amazed Us?
- Mage currently stores over 12 terabytes of time series data across our publishers, and is growing.
- Update from the future: Mage now stores over 50 terabytes of time series data and provides an aggregate view into over 1 petabyte of historical data.
- It allows for horizontal scalability, easy rebuilds/backups, and reliable data distribution.
- Its data sharding scheme satisfies all of our important queries.
- It can handle over 50,000+ real-time writes per second from our data firehose.
- It can return sub-second analytics queries from hundreds of concurrent dashboard users.
Are you a Pythonista who is interested in helping us build Mage? Reach out to work@parsely.com.