Delivering New Historical Analytics
In the past few weeks, our backend engineering team has been hard at work back-populating historical data in Parse.ly’s new dashboard for customers.
Some background: we delivered a version of the new dashboard to a subset of customers who are primarily using it for decision-making over trailing 24 hours of real-time data and trailing 30-day periods of historical data. We were hoping to have historical data ready by August 2015 — the final roadblock to making the new dashboard available to all customers — but some technical challenges led us to delay delivery of this data. The good news is, these technical challenges have been overcome and we are now delivering this historical data in batches to customers!
This post will dive into some of the challenges of back-populating historical data, explain why it took us longer than we expected, and detail what customers can expect in coming weeks as this data comes online.
How do I know I have access to the new dashboard?
Not sure if you have the old or new dashboard? If you still have access to the classic dashboard, the first thing you see upon logging in will look like this:
If you have access to the the new dashboard, the first thing you see upon logging in will be this screen:
This blog post covers the new dashboard. The old dashboard still has 100% of the historical (pageview) data since Parse.ly started tracking for your site.
What challenge did we hit with historical data?
We hit two technical roadblocks with historical data, both of which took us by surprise. In a prior entry of The Changelog, we discussed our new dashboard and its powerful new backend that supports a slew of new metrics. The issue is that over the past 18 months, the volume of data Parse.ly collects has grown by leaps and bounds. This is not just due to new customer go-lives and large sites using Parse.ly; we now measure time-on-page for our customers, which requires analyzing a much larger quantity of data about web visits. This translates to a need for many more servers to process all of that information.
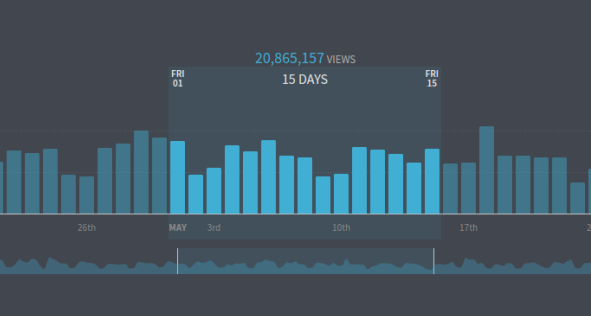
To quantify this a little: some of the largest Parse.ly sites can send us hundreds of millions of events per day. This means we store gigabytes of data per day — per customer. But we have over 400 customers, and most of them are mid-size or large consumer-facing sites. Thus, we had terabytes of data per month to process in order to create historical data records. Providing access to customers requires going back over all of this old data and transforming it for use in the new backend and dashboard.
The other issue is that we discovered, somewhat late in our development process, that an architectural decision we had made earlier in the process created a myriad of issues with historical queries. This is not worth delving into with too much detail, but can be summarized as follows: we thought the best way to store historical data was to roll up metrics by hour, and then derive daily summaries by looking at each group of 24 one-hour periods. But it turned out that the best way to do it was to roll up data by day (24-hour periods) from the get-go. This seemingly small difference had huge implications, both from a correctness and a performance standpoint. So, we knew we had to switch to it!
This combination — a requirement to scale our data processing beyond a level our existing software had been built to handle, as well as a late-stage architectural change in how we stored data — led us to do a rapid sprint of development, which is now wrapping up.
The solution: a new rebuild pipeline
Our engineers knew that the scale problem could be solved by switching to a computing technology that would let us use a huge cluster of machines. We had already been evaluating one of these over the last few months, and decided to dive in and port our historical backpopulation logic to this system. This let us spin up hundreds of CPU cores in the cloud to power through our terabytes of historical data, and process them in parallel.

Further, we started a new data validation project in parallel to verify our switch from hourly to daily rollups. This validation project helped us ensure that the “daily rollups” were just as accurate as the raw data they aggregated over, and that their performance was good. With both of these pieces working, we bought hundreds of thousands of dollars worth of computing infrastructure and set it to work back-populating our customers’ data.
How It Looks and Feels
Check out this animated GIF of the historical analytics in action. Let us know if you have questions about what you can do with the data!
What’s next?
Now that this system is working, we are adhering to the following timeline for relocating all other customer data into this new dashboard.
- Historical data from May 1, 2015 – present was available as of September 18, 2015.
- Historical data from January 1, 2015 – present will be ready by September 29, 2015.
- All historical data, within your account retention limits, will be ready by October 6, 2015.
About The Changelog
The Changelog posts document changes to the Parse.ly dashboard through the eyes of co-founder and CTO, Andrew Montalenti. Interested in trying out the changes for yourself? Login to your Parse.ly account, or sign up to get started with Parse.ly today.