New Product: Parse.ly Data Pipeline

For the past 3 years, Parse.ly has built a strong business around democratized access to real-time and historical analytics. That’s why top sites like TechCrunch, The Intercept, Mashable, and Slate all trust Parse.ly for their day-to-day analytics needs.
But in the past year, we noticed a shift in the industry. Customers are not satisfied with surface-level understanding of their audiences. They understand the value of data — and they want to dig deeper. They’ve hired analysts, product engineers, and data scientists. And they’ve come to us asking, “How can we leverage the awesome infrastructure you’ve built for our new data teams?”
Well, today, we’ve answered the call. Parse.ly just launched its new Data Pipeline product, and we’re very excited to see what analysts, product engineers, and data scientists build with Parse.ly’s scaled data infrastructure available to them as a service.
I’m not just excited about Data Pipeline because we are delivering what our customers want. I’m excited because it means Parse.ly is now available to a much wider group of users — not just publishers and media companies, but anyone who has a considerable user analytics challenge and wants a fast path to insight.
This post will be a broad overview of what the new product is all about.
Building on our experience with real-time data
To date, Parse.ly has had two primary products:
- Parse.ly Dashboard: Our real-time and historical dashboard, which provides instant analytics about content and audiences for hundreds of sites.
- Parse.ly API: Our analytics and recommendation APIs, which provides a simplified way to implement trending content and recommendation modules on websites.
All of Parse.ly’s other development efforts have been in making these two core products essential tools for publishers of all kinds, including things like our iOS app, mobile web experience, full-screen dashboards, and homepage overlay.
The new product is Parse.ly Data Pipeline, which turns all the infrastructure that powers Parse.ly’s analytics offerings into a powerful data management platform for analysts, product engineers, and data scientists.
So, what is a Data Pipeline exactly, and why does your team need one?
Data is about understanding your users
Anyone who runs a site or app of any kind has an audience, that is, users. Data and analytics are powerful tools in understanding your users.
But, in order for your team to truly understand your audience in-depth — to connect their various site/app actions to real business objectives — it needs a reliable data source.
Parse.ly’s Data Pipeline is that source.
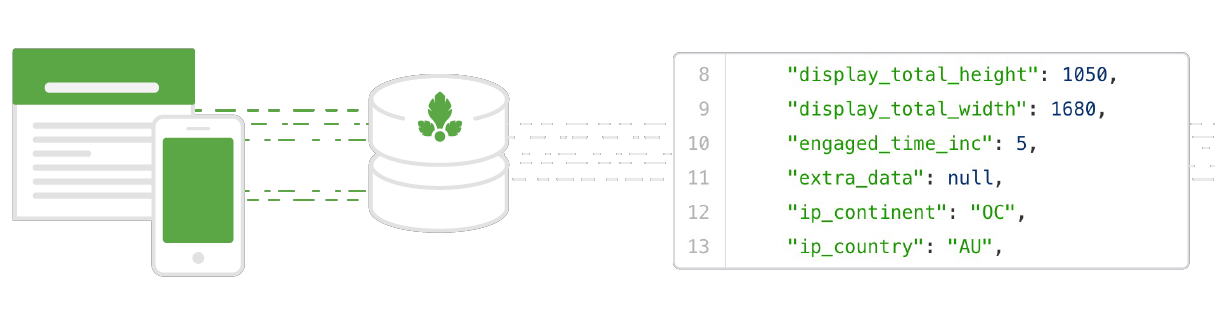
It’s a way to take audience interactions collected across channels — your site, your blog, your mobile app, and anywhere else — and pipe them into secure long-term storage.
Your team can then use this data to run powerful analyses about your audience, using tools they already know and love.
Data Pipeline is about better data with better access
Parse.ly’s Data Pipeline is unique in a number of ways, centered around better data with better access:
- events are in raw form, aka “row-level”, “hit-level”, or “unsampled”
- events are automatically enriched with extra information, like geographic region and device breakouts
- events are highly customizable, so your team can send events of any kind
- Parse.ly’s tracker, by default, collects information that lets you construct a picture of your audience via standard view-, visitor-, and time-based metrics
- Parse.ly’s schema is specifically built for easy import into cloud SQL engines like Redshift and BigQuery
- Parse.ly’s Data Pipeline provides “streaming” access to its real-time events, with end-to-end latency measured in seconds; this will let your team build true real-time dashboards
Save time and take ownership
The key reason to adopt Data Pipeline is to save time and money on an expensive build-out of data infrastructure plumbing, as well as on the painful long-term maintenance of that infrastructure.
But what’s gotten our customers most excited is that it lets them take ownership of their analytics data, in a way that has never been possible before.
The time is now. Your team of analysts and engineers has been itching to put various cloud and open source technologies to use, which have dramatically lowered the barrier to entry for advanced analytics. They’ve been reading about tools like Redshift, BigQuery, and Spark on weekends, and they dream about developing keen insights about your users. But, to date, they’ve been hamstrung by the painful process of standing up expensive data infrastructure, cleaning bad data, and puzzling over archaic vendor APIs.
Well, that’s all over. Now, they can get right to the fun part of their jobs. Parse.ly Data Pipeline is an “easy button” your team can use to build in-house analytics.
A partner you can trust
User data is something Parse.ly takes very seriously. Parse.ly is already used by over 700 top websites and over 170 media companies. We collect data from over 475 million connected devices every month across web and mobile. Our internal data infrastructure — the same one that powers our Data Pipeline — processes over 50 billion user interactions per month.
We have been doing real-time analytics for years, and we provide large-scale audience insights to the teams behind some of the highest-traffic sites around, including TechCrunch, Slate, Mashable, The Telegraph and The New Yorker.
Our backend engineering team include pioneers in streaming analytics and our platform team includes experts in cloud infrastructure.
In short, Parse.ly has solved this problem, and we’ve solved it well. Now your team can benefit — at the flip of a switch.
We look forward to seeing what you build once your team has raw streaming access to your audience data.
Read more on the Data Pipeline overview page.
Next Steps
-
If you are already a Parse.ly customer, get in touch with us, and we’ll be happy to consult you on advanced use cases for your raw data.
-
If you are not a Parse.ly customer, we are glad to schedule a demo where we can share some of the awesome things our existing customers have done with this unlimited flexibility.
-
If you are a developer, check out the official technical documentation, or get an overview via our detailed technical post about how raw data is the ultimate API.